Measurably faster
Measured across 5 complexity levels using the same underlying model.
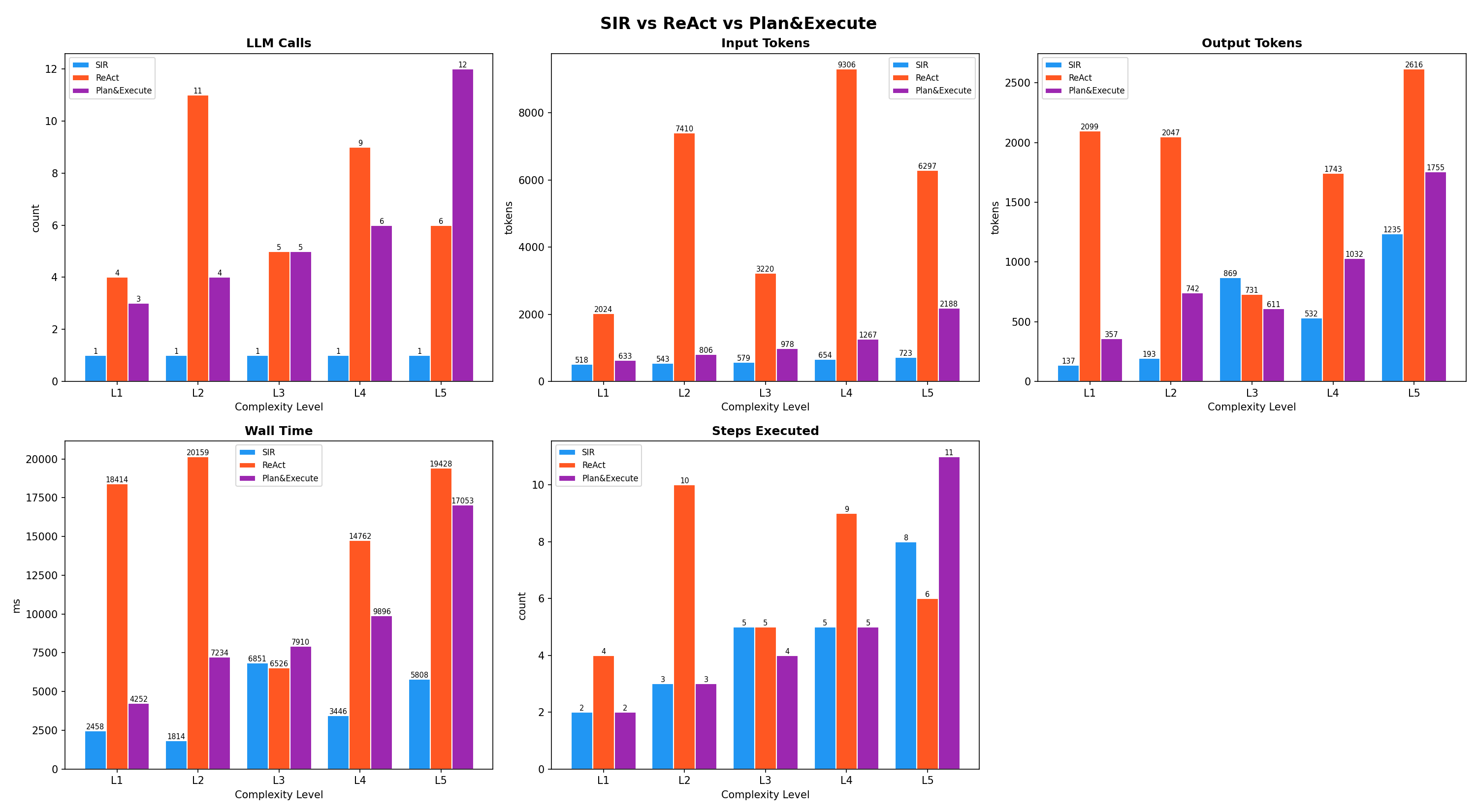
Overview: SIR vs ReAct vs Plan&Execute
Tested across 5 complexity levels (L1: 2 tools through L5: 11 parallel steps) using the same LLM.
ReAct issues one LLM call per step in a loop.
Plan&Execute generates a plan first, then calls the LLM again after each tool execution to summarize.
SIR produces the full DAG in a single call and executes it locally with parallelism.
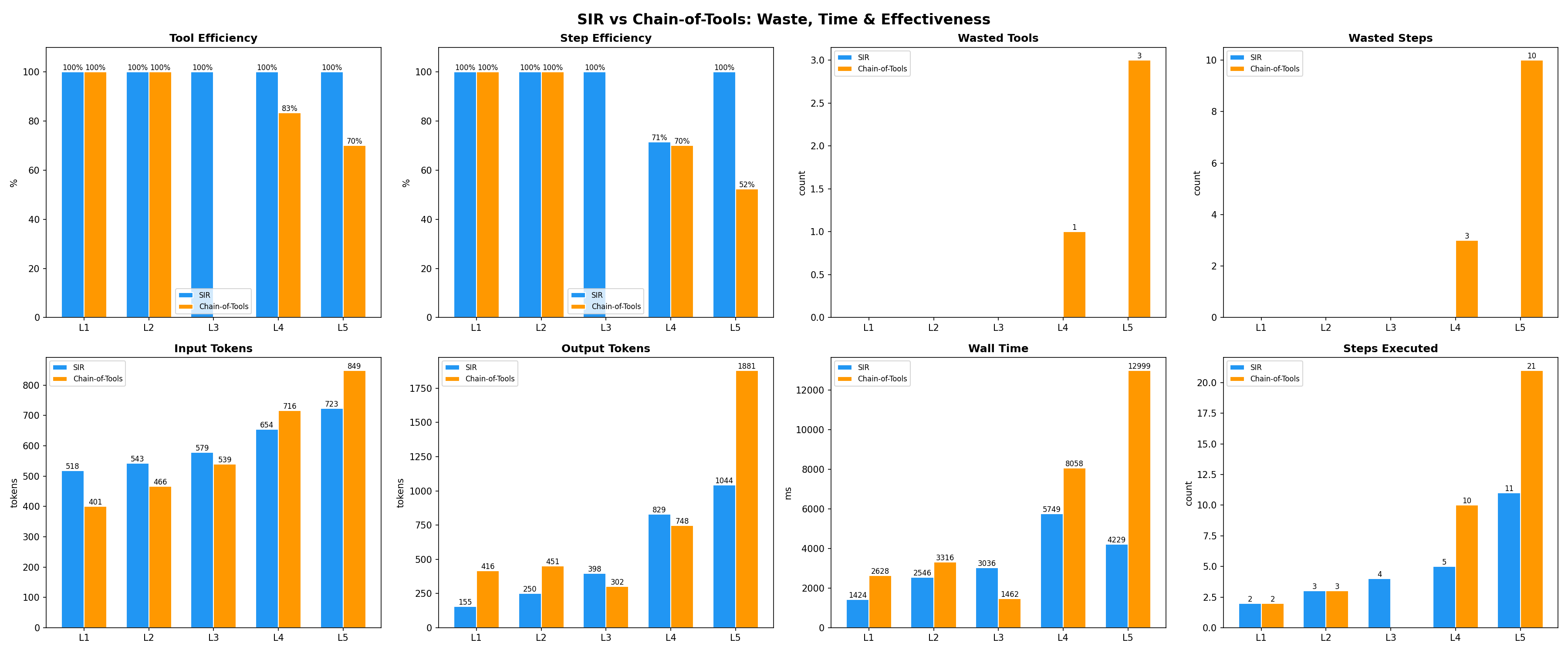
Effectiveness: SIR vs Chain-of-Tools
This benchmark isolates tool selection quality.
Both approaches receive the same tools and the same task.
Chain-of-Tools uses a hardcoded pipeline where the LLM is told which tools to chain, often including unnecessary steps.
SIR adaptively selects only the tools needed.
Metrics: tool efficiency, step efficiency, wasted tools/steps, total tokens, and wall time.